Self-attention
自注意力机制诞生的目的在于实现在以sequence作为输入时同时考虑这个sequence里的所有输入
 图源
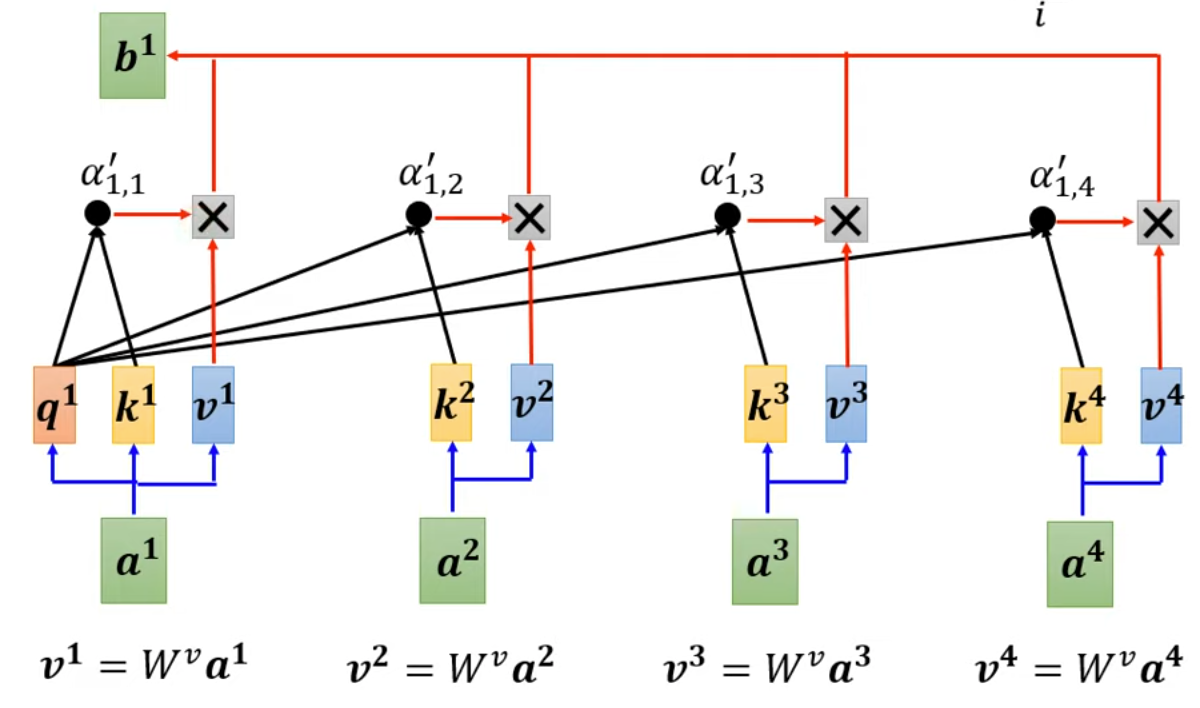
简单来说,其目的即为找到不同的input之间的相关性,从每个输入的角度来看,其先将选定输入向量点乘一个q向量(query),再将所有输入向量乘以一个k向量(key),在分别将乘点乘,得到此向量与别的向量之间的关联。最后我们再分别将各个向量与一个v向量相乘(value)得到最后的输出。
那么我们从线性代数的角度来描述一下上面的过程,假设有一个m*n的输入矩阵I(每一列为一个输入共n个),那么则有三个均为m*m的查询矩阵W^q^, W^k^,W^v^,随后我们就可以相乘获得矩阵Q,K,V=W^q^*X, W^k^*X, W^v^*X(m*n),而后得到注意力分数矩阵A=K^T^*Q(n*n),最后得到输出O=V*A(m*n)
事实上这里可以优化一下运算量,即最终输出为O=V*K^T^*Q此处可以将前两项相乘,可以节约部分运算量。
图源
简单来说,其目的即为找到不同的input之间的相关性,从每个输入的角度来看,其先将选定输入向量点乘一个q向量(query),再将所有输入向量乘以一个k向量(key),在分别将乘点乘,得到此向量与别的向量之间的关联。最后我们再分别将各个向量与一个v向量相乘(value)得到最后的输出。
那么我们从线性代数的角度来描述一下上面的过程,假设有一个m*n的输入矩阵I(每一列为一个输入共n个),那么则有三个均为m*m的查询矩阵W^q^, W^k^,W^v^,随后我们就可以相乘获得矩阵Q,K,V=W^q^*X, W^k^*X, W^v^*X(m*n),而后得到注意力分数矩阵A=K^T^*Q(n*n),最后得到输出O=V*A(m*n)
事实上这里可以优化一下运算量,即最终输出为O=V*K^T^*Q此处可以将前两项相乘,可以节约部分运算量。
multi-head Self-attention
若只考虑“一种相关性”还不够的话,不妨考虑一下使用多头的机制,即设定有多个W^q^, W^k^, W^v^矩阵,最后得到多个O再乘一个新的W^O^变换矩阵得到最终的输出。
positional encoding
在原始的自注意系统中,虽然可以寻找不同输入之间的关联,但并不能察觉不同输入的位置关系,因此我们可以加入positional encoding,最简单的一种实现方式就是在输入矩阵输入前加一个可以表示位置的矩阵(比如 np.diag([0,1,2,3,4...]))
Transformer
Transformer是一种广泛采用的sequence to sequence(seq2seq)的模型,即输入的长度与输出的长度都不定,这类模型在如翻译等方面有着非常广泛的应用(翻译后的文字长度不定)。也是大语言模型的重要基础。
 图源
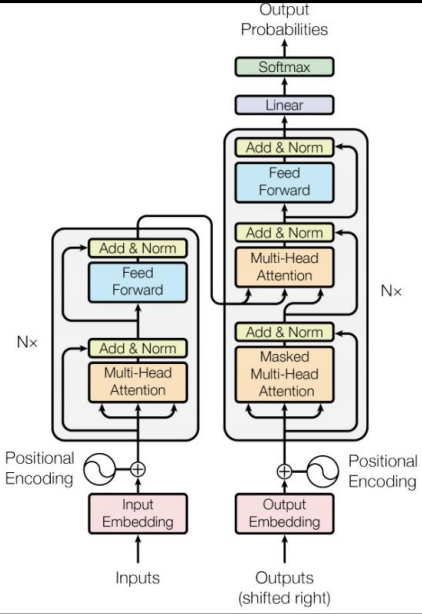
transformer的架构被分为两部分,encoder(左)和decoder(右)
图源
transformer的架构被分为两部分,encoder(左)和decoder(右)
Encoder> reference
在输入进行embedding和positional encoding之后,先进入一个multi-head attention层,然后在Add&Norm层加上原输入(残差设计)和进行Normalization,再进入一个Feed Foward层(全连接层)再进行一次Add&Norm(这一整个流程可以重复多次)
Decoder
我们可以发现decoder的输入和输出是同一形状的,所以transformer要实现不定长度的输出主要依靠后半部分的decoder。我们知道其本身就是生成一系列字符,那么解决办法就是将休止符也加入奖池当中,什么时候抽到END什么时候结束。 那么其生成方式也有两种,AT(autoregressive)和 NAT(non-autoregressive),第一个是一步一步慢慢来的,也就是第一部decoder先吃一个start,然后进行一次输出,再将这个输入重新喂进模型,再过一次模型,如此往复直到输出结果为END。 那么Non-autoregressive则是试图一步到位的尝试,那么如何做到一步到位呢,比较简单的方法一个是单独再训练一个classifier来决定结果的长度,或者所幸一次性向里面扔足够长的输入值,然后看哪一位生成了END,然后直接取END前的作为最终输出。 如上我们可以发现NAT在准确性上显然远远不如AT,不过由于其有速度快等特性,因此优化其训练准确度也是研究的热门方向之一
Masked Multi-Head Attention
先前我们设计的Self-attention部分是一次性考虑整个输出的内容,而在Decoder阶段的吃一个吐一个的情况下,“考虑整段”显然是个没有意义的情况,此处的masked的效果即是,在计算attention matrix的时候只考虑自身与自身之前的输入序列,不考虑之后的输出序列。
cross-attention
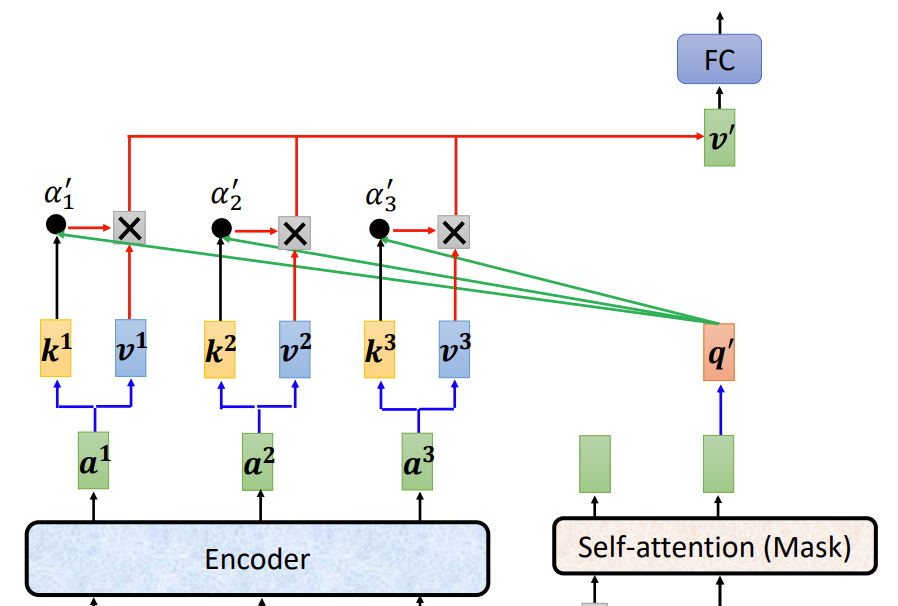
在decoder第二阶段,将encoder输出和decoder第一阶段输出同时输入一个masked multi-head attention层中,也就是算decoder输出和encoder输出的相关性,这里我们把他就叫做cross-attention
 图源
图源
训练方法与更多拓展
- Teacher Forcing:在AT的情况下,一个输出与上一个输出之间有很强的关联,若上一个输出出问题,那么下一个输出也大概率下会寄,若训练时不加干涉任其一错再错,很可能会导致训练效率较差,那么我们可以在训练的时候始终传入正确的输入,降低发生连锁错误的概率,优化训练方式。
- Schedule Sampling:不过Teacher Forcing的方法还是有问题,若模型在测试的时候一直都用的是正确的答案作为输入,那在测试的时候还是一旦错了就废了,所以我们又不能一直输入正确答案,也要在训练的时候人工加入一些错误答案,也就是Schedule Sampling
水多加面面多加水的感觉 - Guided Attention:原始的Attention的结构中,模型会平等地看待序列中每一份输入之间的相关性,在某些条件下我们可能更需要模型去特定地关注某一部分的相关性,那我们就可以引入额外的权重等方式来人为干预attention score的产生。
- Beam Search:假设输出是一段中文文字(比如翻译任务,或者大语言模型),每次输出都是从字符库里选出那个概率最大的可能性,那么不难发现我们的输出实际上是一个分类问题,只是这个分类的备选种类有点点多,那么每次都要穷举所有的分类组合是比较耗时的,但是若是贪心算法有可能面临局部最佳并非全局最佳的情况,因此在二者之间就开发了一个折衷的Beam Search的算法,其实也还是贪心,只是每次不只是保留最高的得分的那个,而是保留数个较高的得分,兼顾了贪心算法的速度和穷举的准确性,同时也可以通过如Length Penalty等方式认为控制beam search的细节。
- 各式各样的attention:由前面我们不难知道attention中最大的瓶颈就在attention matrix的计算上(n^2^),那么,我们能不能想办法优化这部分呢,最简单的方法就是只计算一部分重要的attention score就可以了,那么怎么界定一个attention score重不重要呢,一种方法就是人为制定哪些需要计算哪些不需要计算(比如可以规定只考虑一个输入和其前后有限项的关联程度,即local attention,当然这个的实质和CNN就差不多了🤣)等等,或者你也可以利用如聚类分析等方法将一个决定哪些attention score需要计算这件事本身也作为模型的一部分。
Reference